The idea was to use what we call provenance, i.e. we record all the information from the very beginning as well as the flow of data, and we use this to build explanations that address some important legal requirements.
Professor Luc Moreau
10 May 2022
Cracking the black box
Guest writer, Juljan Krause from University of Southampton, takes a look at provenance in AI.
How King's researchers build a provenance-based system to make AI explainable.

Introduction
AI and machine learning have been the subject of a great deal of controversy over the past couple of years: a steady outpour of cases reveal how automated systems have denied bank loans to applicants on dubious grounds, refused job applications from under-represented groups or recommended harsher prison sentences for ethnic minority defendants. In many instances, existent biases would feed into automated systems and perpetuate them with no obvious ill intent, which makes it hard to identify who is ultimately responsible for discriminatory practices. Today, the serious challenges of systems that make unfair decisions and are prone biases on the grounds of race, gender or health are being discussed widely in the media.
To many decision makers and members of the public, automated systems seem to operate like a ‘black box’. This causes a real headache for public and private organisations that fear the legal repercussions of implementing flawed systems of this sort. The potential costs of high-profile court cases, both in financial and reputational terms, are considerable. Calls are mounting to deploy only systems that are explainable in that the reasoning behind machine decisions can be traced back and evaluated retrospectively. In the US, legislators currently debate the ‘Algorithmic Accountability Act’ that would require organisations to conduct robust AI fairness checks. For the European Commission, explainability has emerged ‘as a key element for a future regulation’ of AI beyond existing measures enshrined in the GDPR, such as in Article 13 of the recently proposed AI Act. And in the UK, even the intelligence service GCHQ has joined the debate and promises to build on Explainable AI wherever possible.
With explainability gaining so much traction and attention, the big-prize question emerges, how can it be achieved in practice? How can abstract demands for transparency and accountability translate into actual AI design principles? Explainability itself is an umbrella term for a whole bag of fine-grained concepts and several engineering approaches compete in this space. A team at King's Department of Informatics offers a unique perspective on the complex challenge of Explainable AI: if we wish to explain the decision a system makes, let’s take a closer look at the processes of how it gets there, how it has been configured in the first place and what kinds of data it uses.
King's provenance-based approach
To make headway on this sizeable problem, the team of Professor Luc Moreau and Dr Trung Dong Huynh and their project partners from the University of Southampton collaborated with the UK’s Information Commissioner’s Office (ICO). They’ve set themselves the following challenge: can we build a proof of concept for an automated decision-making system that provides details of meaningful, interpretable decisions at each step of the way? Any such system would have to meet Article 15 of the GDPR, which explicitly states that ‘data controllers’, i.e. anyone who collects and uses data, must be able to provide ‘meaningful information about the logic involved’ in automated decisions. ‘Leveraging technology to see how socio-technical systems are constituted is a way to address their inherent opacity, as long as the explanations that are generated support rather than substitute human intervention’, Professor Sophie Stalla-Bourdillon from the University of Southampton explains. ‘Provenance offers the possibility to de-construct automated decision-making pipelines and empower both organisations to reach a high level of accountability and individuals to take action and exercise their rights’.
Over the course of only a couple of months, the team has delivered some impressive results. Professor Moreau explains:
The team used the W3C’s tried and tested PROV-DM data model to build a knowledge graph for a hypothetical lender that makes semi-automated decisions about loan applications. Provenance maps and records in full the activities between all entities involved. The process of applying for a loan, the application being evaluated, and a decision being made all leave a substantial audit trail that can be used to query the system at a later stage about why it has proceeded in the ways it did.
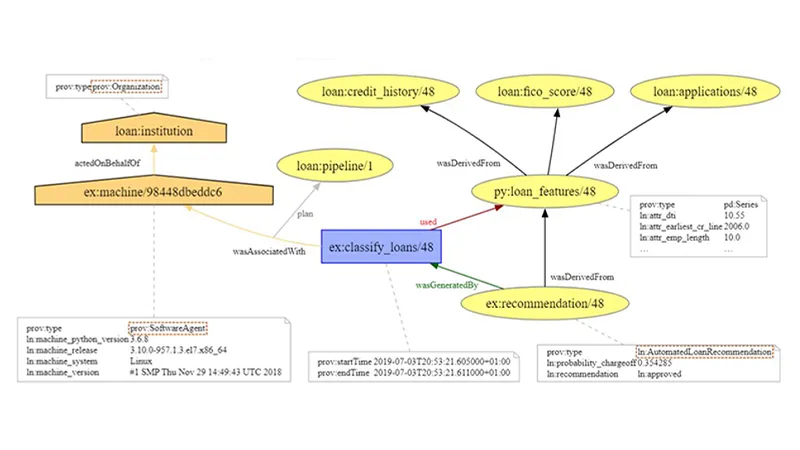
However, a full provenance record would be information overkill and of not much use to anyone. To make the system useful, the team identified 13 categories of potential explanation categories that the hypothetical loan pipeline could draw up. To produce targeted information, each category is mapped to a pre-defined explanation framework. Upon being queried, it adds the relevant parts from the provenance record to a Natural Language narrative template: the output is a piece of text which is intelligible to human readers and explains why, for instance, a loan application has been rejected. Users are presented with a detailed breakdown of all decision variables involved, and receive responses to possible questions that they may have regarding their loan application:
King's provenance-based approach
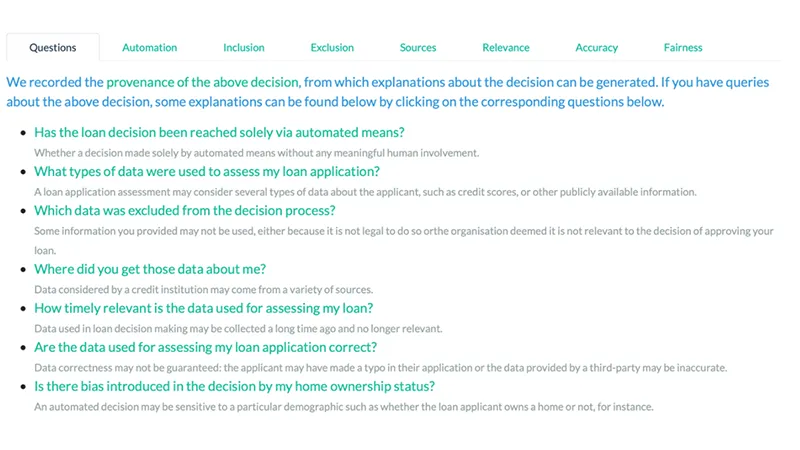
Upon clicking on any of the above questions, the system provides a detailed account of the relevant nodes involved and their relationships, e.g. if the decision did in fact involve human oversight or not, and which credit scores were used.
What’s the impact been so far?
King's provenance-based approach has caught attention from a range of experts in multidisciplinary teams. The initial findings and a technical report have been published in the peer-reviewed ACM journal Digital Government: Research and Practice. ‘On top of that we’ve also launched a demo page for everyone to give it a go’, Dr Huynh adds.
The ICO considers the findings of the project extremely important. So much so that they include the team’s work in their official recommendations for all organisations that collect and process data. Prominently placed on their list of guidelines for building an explainable data model, the ICO now showcases King's provenance-based approach as an example. ‘We’re obviously very pleased that our work has been acknowledged by the ICO, and listed as one of the technical approaches to producing explanations’, Professor Moreau says.

In their work, Professor Moreau and his team draw on the deep expertise and wide-ranging areas of research at King's Department of Informatics in the domain of Artificial Intelligence. King’s College London is home to the UKRI’s Centre for Doctoral Training in Safe and Trusted Artificial Intelligence (STAI), which is led by King’s in partnership with Imperial College London. King's Department of Informatics is also heavily involved in the newly launched UKRI flagship programme, the Trustworthy Autonomous System (TAS) Hub where Professor Moreau serves as Deputy Director. And the AI project THuMP also seeks to advance state-of-the-art Explainable AI. The team’s provenance-based approach slots in nicely with King's considerable AI portfolio.
Looking ahead: the next steps
Given the early successes and wide impact of the project there is no stopping the team at this point. Codenamed PLEAD – Provenance-driven and Legally-grounded Explanations for Automated Decisions – the project has evolved into a much larger activity. Partnering with the University of Southampton, Southampton City Council as well as industry partners Experian and Roke, Professor Moreau’s team aims to develop and extend the provenance-based approach to a whole range of legal requirements that UK businesses face. Professor Moreau elaborates:
In PLEAD, our aim is to operationalise the methodology and a software system called “Explanation Assistant”, to allow organisations to adopt the system and integrate it to address their business needs.
Professor Luc Moreau
Funded by the EPSRC with a grant of £600K, PLEAD seeks to deliver a dedicated Explanation Assistant tool for any UK data controller to vastly extend their explanation capabilities. The team has already a delivered a series of talks and published a set of papers on this issue, with targeted workshops scheduled for later this year. With demands for truly Explainable AI growing from legislators and civil society actors alike, PLEAD can’t deliver its tool soon enough: in the near term, businesses can expect a regulatory shakeup that will leave no more room for black box AI.