25 May 2022
Explainability by design
Written by Luc Moreau, Dong Huynh
There are increasing calls for explainability of data-intensive applications. Such a demand for explainability stems from various reasons, such as regulations, governance frameworks or business drivers.
A methodology to support explanations in decision-making systems
There are increasing calls for explainability of data-intensive applications. Such a demand for explainability stems from various reasons, such as regulations, governance frameworks or business drivers. Explanations are becoming a mechanism to demonstrate good governance of data-processing pipelines. Good explanation capability should be able to answer a vast range of queries including the following “Was consent obtained from the user to process their data?”, “What process was followed to check a model before its deployment?”, “What are the factors that influenced a decision”, “What action could be taken to correct some data”, and “Is the actual execution of the Data Science application complying with a given data governance framework?”.
So far, there has been a lack of a principled approach to generating explanations. From an implementation viewpoint, there is no good separation of concerns between decision-making systems, their querying, and the composition of explanations. From a methodological viewpoint, there is not a well-specified workflow for engineers to follow, which leaves every organisation to “reinvent the wheel” for their explanation capability.
Against this background, we introduce “Explainability by Design” a methodological approach which tackles this issue in the design and architecture of IT systems and business practices. Explainability-by-Design (EbD) is a methodology that is characterised by proactive measures to include explanations in the design rather than relying on reactive measures to bolt on explanation capability after the fact, as an add-on.
A key aspect in the journey of developing a methodology is to understand what an explanation is, and all the properties it is intended to satisfy. To this end, I will outline a taxonomy of explanations and their requirements.

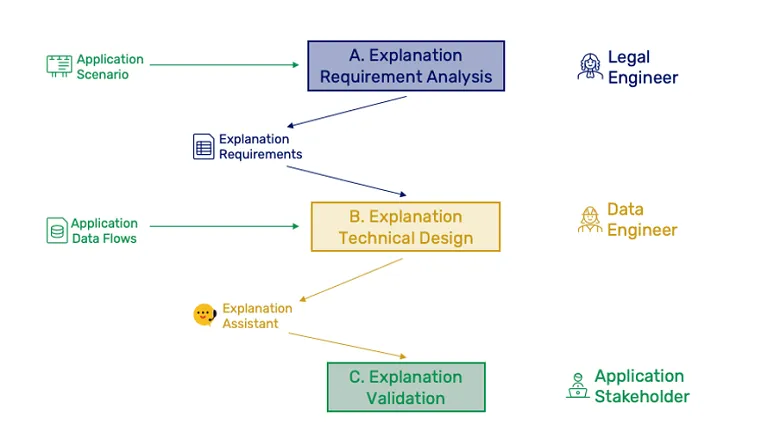
Another aspect of this journey is to conceptualise an explainability component as an integral part of a business system, enriching its functionality with capabilities that can address regulatory requirements but also functional and business needs. We have produced a reference implementation of this component, which is called the Explanation Assistant. A configured and ready-to-be-deployed Explanation Assistant is a key output of the Explainability-by-Design methodology.
The final aspect is the breaking down of the methodology into steps ingesting explanation requirements in order to construct an explanation capability that a system’s triggers can activate, in order to generate the required explanations.
The above steps of the methodology are to be carried out by various roles in an organisation. The socio-technical Engineer focuses on the requirement analysis, leading to a set of explanation requirements that the Data Engineer processes in order to produce a configuration of the explanation assistant that can be validated by the Application Stakeholder.
Luc’s presentation at ODSC Europe 2022 will further motivate the methodology and will dive into the various steps of a well-specified workflow, which should be carried out by the Data Engineer.
In this story

Research Fellow